Chapter 3
Data Handling using Pandas – II
1. Write the statement to install the python connector to connect MySQL i.e. pymysql.
Answer:
2. Explain the difference between pivot() and pivot_table() function?
Answer:
3. What is sqlalchemy?
Answer:
4. Can you sort a DataFrame with respect to multiple columns?
Answer:
5. What are missing values? What are the strategies to handle them?
Answer:
6. Define the following terms: Median, Standard Deviation and variance.
Answer:
7. What do you understand by the term MODE? Name the function which is used to calculate it.
Answer:
8. Write the purpose of Data aggregation.
Answer:
9. Explain the concept of GROUP BY with help on an example.
Answer:
10. Write the steps required to read data from a MySQL database to a DataFrame.
Answer:
11. Explain the importance of reshaping of data with an example.
Answer:
12. Why estimation is an important concept in data analysis?
Answer:
13. Assuming the given table: Product. Write the python code for the following:
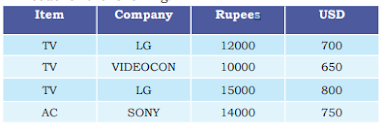
a) To create the data frame for the above table.
Answer:
b) To add the new rows in the data frame.
Answer:
c) To display the maximum price of LG TV.
Answer:
d) To display the Sum of all products.
Answer:
e) To display the median of the USD of Sony products.
Answer:
f) To sort the data according to the Rupees and transfer the data to MySQL.
Answer:
g) To transfer the new dataframe into the MySQL with new values.
Answer:
14. Write the python statement for the following question on the basis of given dataset:
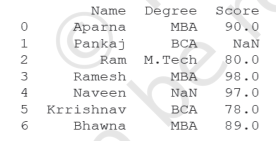
a) To create the above DataFrame.
b) To print the Degree and maximum marks in each stream.
c) To fill the NaN with 76.
d) To set the index to Name.
e) To display the name and degree wise average marks of each student.
f) To count the number of students in MBA.
g) To print the mode marks BCA.
Answer:
Solved Case Study based on Open Datasets UCI dataset is a collection of open datasets, available to the public for experimentation and research purposes. ‘auto-mpg’ is one such open dataset.
It contains data related to fuel consumption by automobiles in a city. Consumption is measured in miles per gallon (mpg), hence the name of the dataset is auto-mpg. The data has 398 rows (also known as items or instances or objects) and nine columns (also known as attributes).
The attributes are: mpg, cylinders, displacement, horsepower, weight, acceleration, model year, origin, car name. Three attributes, cylinders, model year and origin have categorical values, car name is a string with a unique value for every row, while the remaining five attributes have numeric value.
The data has been downloaded from the UCI data repository available at http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/. Following are the exercises to analyse the data.
1) Load auto-mpg.data into a DataFrame autodf.
2) Give description of the generated DataFrame autodf.
3) Display the first 10 rows of the DataFrame autodf.
4) Find the attributes which have missing values. Handle the missing values using following two ways:
i. Replace the missing values by a value before that.
ii. Remove the rows having missing values from the original dataset
Answer:
5) Print the details of the car which gave the maximum mileage.
Answer:
6) Find the average displacement of the car given the number of cylinders.
Answer:
7) What is the average number of cylinders in a car?
Answer:
8) Determine the no. of cars with weight greater than the average weight.
Answer: